High-performance JSON codec
2021-02-01 22:52:44 +0000 by Dong
JSON processing is a fundamental building block in modern network applications. It’s also a large module in Z-Data package. With careful optimization, we managed to get a 1.5X - 3X encoding and 3X decoding performance boost comparing to aeson, a widely used JSON package on hackage.
Benchmark Result
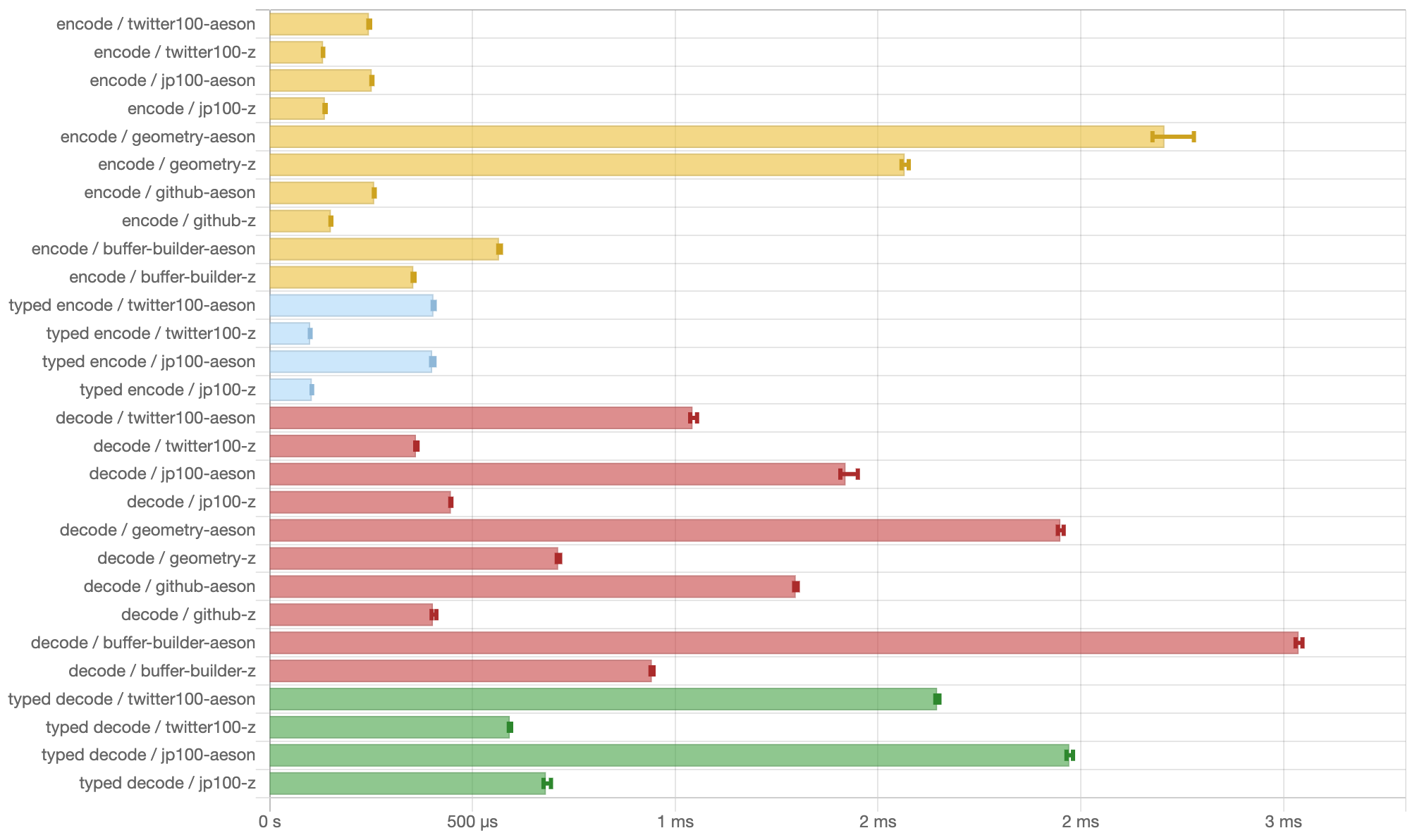
The above benchmarks running on an MBP13 2020(2 GHz Quad-Core Intel Core i5), Each benchmark runs a certain JSON task with fixed iterations, using sample data. Some notes on benchmarks code:
- Benchmarks labeled with
encodeanddecodebench the conversion between JSON documents and JSON intermedia representation. - Benchmarks labeled with
typed encodeandtyped decodebench the conversion between JSON documents and Haskell ADT. - All ADTs’ instances are deriving using GHC generic mechanism, no manual conversion code is required.
Fast escaping handling
Surprisingly, when processing JSON, one can’t directly copy strings because they may be escaped, which brings a quite big performance challenge. In Z-Data we carefully arranged the code path to avoid performance hit:
-
When encoding text value
- Run a prescan loop to find if we need escaping, and how much space we need to write the escaped string if escaping is needed.
- If there’s no escaping needed, vectorized
copyByteArray#is used to directly write text into the output buffer. - Otherwise, go through the escaping loop.
-
When decoding JSON string
- Run a prescan to find the end of the string, record if unescaping is needed at the same time.
- If no unescaping is needed, a vectorized UTF8 validation is used.
- Otherwise, go through a UTF8 validation loop extended with JSON unescaping logic.
These optimizations are possible because Z-Data uses UTF8 encoding Text type, which could save considerable time on the non-escaping path.
IR(intermedia represantation)
Another optimization opportunity comes from the new JSON document IR design. In Z-Data the IR type use vector of key-value pair to represent JSON objects:
data Value = Object (Vector (Text, Value))
| Array (Vector Value)
| String T.Text
| Number Scientific
| Bool Bool
| Null
deriving (Eq, Ord, Show, Typeable, Generic)
deriving anyclass Print
This representation has many benefits:
- Preserve original key-value order, so that round-trip processing is possible.
- User can choose different de-duplicate strategys when converting IR to ADT.
- It’s faster to construct an IR value or convert ADT to IR.
By default Z-Data use FlatMap when converting IR to ADT, which is simply a sorted vector of key-value pair. It can be constructed by sorting the original key-value pairs in O(N*logN) and looked up using binary-search in O(logN).
Parser and Builder facility
Z-Data uses Bytes, a vector type based on ByteArray# to represent binary data, it’s different from traditional bytestring ones that use Addr#(pointer). It’s necessary to provide a different set of Builders and Parsers to work on that representation. In both cases, simple CPSed monad is chosen to make compiled code fast.
-- Z.Data.Builder.Base
newtype Builder a = Builder {
runBuilder :: (a -> BuildStep) -- next write continuation
-> BuildStep
}
-- Z.Data.Parser.Base
newtype Parser a = Parser {
runParser :: forall r . (ParseError -> ParseStep r) -- fail continuation
-> (a -> ParseStep r) -- success continuation
-> ParseStep r
}
These types are almost the simplest CPS monads one can write, and GHC is particularly good at optimizing the composition of these monads.
Conclusion
This benchmark compared Z-Data to widely used Haskell package aeson. The result shows that the new Builder and Parser facility works as expected, and our optimizing techniques can bring a huge performance improvement.